By my measure, Fiona is half-way to production readiness. Version 0.5 is up on
PyPI: http://pypi.python.org/pypi/Fiona/0.5. It now writes mapping features to
almost any of OGR's formats. Almost.
In Python, I'm not very interested in OGR's support for databases or services,
and so Fiona isn't either. I'd rather use httplib2 to connect fetch any JSON or
XML (KML, GML, GeoRSS) document on the web, and Python's built-in json or
xml.etree modules to parse them with some help from geojson and keytree. For
databases, I'll use SQLAlchemy or GeoAlchemy. Fiona is mainly about reading and
writing the arcane file formats like shapefiles, GPX, etc for which there is
pretty much no other access than through OGR's drivers. Fiona doesn't do OGR
"data sources". It has collections of a single feature type. Think shapefile or
single PostGIS table. The door isn't completely shut on databases; the first
version of Fiona had the concept of a "workspace", and we could bring that back
if needed.
The latest installation instructions and usage example are on Fiona's GitHub
page: https://github.com/sgillies/Fiona and there's more documentation to come.
A Shapely-level manual will be the cornerstone of a 1.0 release, although
I expect the Fiona manual to be much smaller.
Installation
If you've got GDAL installed in a well-known location and Python 2.6, you may be
able to install as easily as:
If, like me, you have virtualenvs with their own GDAL libs, you'll need to do
something like this.
$ virtualenv .
$ source bin/activate
$ pip install -d Fiona http://pypi.python.org/packages/source/F/Fiona/Fiona-0.5.tar.gz
$ export GDAL=${PATH_TO_GDAL}
$ cd Fiona
$ python setup.py build_ext -I ${GDAL}/include -L ${GDAL}/lib install
Reading benchmark
Is Fiona anywhere as fast as osgeo.ogr? Benchmark: get all polygon-type
features from a shapefile, read their attributes into a dict, get a reference
to their geometry (in the OGR case) or geometry as GeoJSON (in the Fiona
case), and get their unique ids. Here's the script:
import timeit
from fiona import collection
from osgeo import ogr
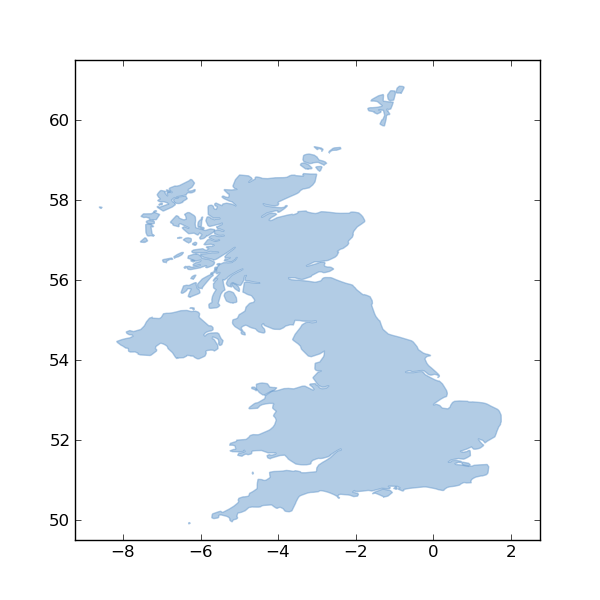
PATH = 'docs/data/test_uk.shp'
NAME = 'test_uk'
# Fiona
s = """
with collection(PATH, "r") as c:
for f in c:
id = f["id"]
"""
t = timeit.Timer(
stmt=s,
setup='from __main__ import collection, PATH, NAME'
)
print "Fiona 0.5"
print "%.2f usec/pass" % (1000000 * t.timeit(number=1000)/1000)
print
# OGR
s = """
source = ogr.Open(PATH)
layer = source.GetLayerByName(NAME)
schema = []
ldefn = layer.GetLayerDefn()
for n in range(ldefn.GetFieldCount()):
fdefn = ldefn.GetFieldDefn(n)
schema.append((fdefn.name, fdefn.type))
layer.ResetReading()
while 1:
feature = layer.GetNextFeature()
if not feature:
break
id = feature.GetFID()
props = {}
for i in range(feature.GetFieldCount()):
props[schema[i][0]] = feature.GetField(i)
geometry = feature.GetGeometryRef()
feature.Destroy()
source.Destroy()
"""
print "osgeo.ogr 1.7.2"
t = timeit.Timer(
stmt=s,
setup='from __main__ import ogr, PATH, NAME'
)
print "%.2f usec/pass" % (1000000 * t.timeit(number=1000)/1000)
That's just 3 statements with Fiona, 19 with osgeo.ogr. Do you like that? I like
that. A lot. Next are the numbers.
(Fiona)krusty-2:Fiona seang$ python benchmark.py
Fiona 0.5
2579.40 usec/pass
osgeo.ogr 1.7.2
3355.43 usec/pass
Result: even though Fiona is doing a fair amount of extra coordinate copying,
it's still faster than the Python bindings for OGR 1.7.2. Simpler + faster seems
like a big win.
Writing benchmark
How about writing speed? Benchmark: open a shapefile for writing and write 50
identical (other than their local ids) point-type features to it.
import os
import timeit
from fiona import collection
from osgeo import ogr
FEATURE = {'id': '1', 'geometry': {'type': 'Point', 'coordinates': (0.0, 0.0)},
'properties': {'label': u"Foo"}}
SCHEMA = {'geometry': 'Point', 'properties': {'label': 'str'}}
# Fiona
s = """
with collection("fiona.shp", "w", "ESRI Shapefile", SCHEMA) as c:
for i in range(50):
f = FEATURE.copy()
f['id'] = str(i)
c.write(f)
"""
t = timeit.Timer(
stmt=s,
setup='from __main__ import collection, SCHEMA, FEATURE'
)
print "Fiona 0.5"
print "%.2f usec/pass" % (1000000 * t.timeit(number=1000)/1000)
print
# OGR
s = """
drv = ogr.GetDriverByName("ESRI Shapefile")
if os.path.exists('ogr.shp'):
drv.DeleteDataSource('ogr.shp')
ds = drv.CreateDataSource("ogr.shp")
lyr = ds.CreateLayer("ogr", None, ogr.wkbPoint)
field_defn = ogr.FieldDefn("label", ogr.OFTString)
lyr.CreateField(field_defn)
for i in range(50):
feat = ogr.Feature(lyr.GetLayerDefn())
feat.SetField("label", u"Foo")
pt = ogr.Geometry(ogr.wkbPoint)
x, y = FEATURE['geometry']['coordinates']
pt.SetPoint_2D(0, x, y)
feat.SetGeometry(pt)
feat.SetFID(i)
lyr.CreateFeature(feat)
feat.Destroy()
ds.Destroy()
"""
print "osgeo.ogr 1.7.2"
t = timeit.Timer(
stmt=s,
setup='from __main__ import ogr, os, FEATURE'
)
print "%.2f usec/pass" % (1000000 * t.timeit(number=1000)/1000)
Fiona only needs five statements compared to 18 for osgeo.ogr, and Fiona writes
these features faster.
(Fiona)krusty-2:Fiona seang$ python write-benchmark.py
Fiona 0.5
4435.63 usec/pass
osgeo.ogr 1.7.2
4565.33 usec/pass
I was rather surprised by this. I've been benchmarking feature reading for a while
but this is the first time I've done it for writes.
Tests
Do you like tests?
(Fiona)krusty-2:Fiona seang$ python setup.py nosetests --nologcapture --with-coverage --cover-package=fiona
running nosetests
running egg_info
writing src/Fiona.egg-info/PKG-INFO
writing top-level names to src/Fiona.egg-info/top_level.txt
writing dependency_links to src/Fiona.egg-info/dependency_links.txt
reading manifest file 'src/Fiona.egg-info/SOURCES.txt'
reading manifest template 'MANIFEST.in'
warning: no files found matching '*.txt' under directory 'tests'
writing manifest file 'src/Fiona.egg-info/SOURCES.txt'
running build_ext
copying build/lib.macosx-10.5-i386-2.6/fiona/ogrinit.so -> src/fiona
copying build/lib.macosx-10.5-i386-2.6/fiona/ogrext.so -> src/fiona
nose.config: INFO: Ignoring files matching ['^\\.', '^_', '^setup\\.py$']
nose.plugins.cover: INFO: Coverage report will include only packages: ['fiona']
test_invalid_mode (tests.test_collection.CollectionTest) ... ok
test_no_path (tests.test_collection.CollectionTest) ... ok
test_w_args (tests.test_collection.CollectionTest) ... ok
test_append_point (tests.test_collection.ShapefileAppendTest) ... ok
test_context (tests.test_collection.ShapefileCollectionTest) ... ok
test_filter_1 (tests.test_collection.ShapefileCollectionTest) ... ok
test_io (tests.test_collection.ShapefileCollectionTest) ... ok
test_iter_list (tests.test_collection.ShapefileCollectionTest) ... ok
test_iter_one (tests.test_collection.ShapefileCollectionTest) ... ok
test_len (tests.test_collection.ShapefileCollectionTest) ... ok
test_no_write (tests.test_collection.ShapefileCollectionTest) ... ok
test_schema (tests.test_collection.ShapefileCollectionTest) ... ok
test_no_read (tests.test_collection.ShapefileWriteCollectionTest) ... ok
test_write_point (tests.test_collection.ShapefileWriteCollectionTest) ... ok
test_write_polygon (tests.test_collection.ShapefileWriteCollectionTest) ... ok
test_linestring (tests.test_feature.PointTest) ... ok
test_point (tests.test_feature.PointTest) ... ok
test_polygon (tests.test_feature.PointTest) ... ok
test (tests.test_geometry.GeometryCollectionRoundTripTest) ... ok
test (tests.test_geometry.LineStringRoundTripTest) ... ok
test_line (tests.test_geometry.LineStringTest) ... ok
test (tests.test_geometry.MultiLineStringRoundTripTest) ... ok
test_multilinestring (tests.test_geometry.MultiLineStringTest) ... ok
test (tests.test_geometry.MultiPointRoundTripTest) ... ok
test_multipoint (tests.test_geometry.MultiPointTest) ... ok
test (tests.test_geometry.MultiPolygonRoundTripTest) ... ok
test_multipolygon (tests.test_geometry.MultiPolygonTest) ... ok
test (tests.test_geometry.PointRoundTripTest) ... ok
test_point (tests.test_geometry.PointTest) ... ok
test (tests.test_geometry.PolygonRoundTripTest) ... ok
test_polygon (tests.test_geometry.PolygonTest) ... ok
Name Stmts Miss Cover Missing
------------------------------------------------
fiona 15 0 100%
fiona.collection 56 0 100%
------------------------------------------------
TOTAL 71 0 100%
----------------------------------------------------------------------
Ran 31 tests in 4.955s
OK
I haven't figured out how to get Fiona's OGR extension module covered, but I'd
be surprised if it wasn't > 90%.
I've been telling people that Fiona's objective was 80% of osgeo.ogr's
functionality at 20% of the complexity. Maybe it can have 5% better
performance, too?
Re: Fiona's half-way mark
Author: NathanW
>>That's just 3 statements with Fiona, 19 with osgeo.ogr. Do you like that? I like that.
Like it? Love it! So much cleaner; less stuffing around just get in and do what you what. The less red (read: noise code) the better.
Keep up the good work! Looking at ways I can apply the same kind of API logic to QGIS, as the API is a little verbose sometimes just to do simple thing.
Any reason why you use f['id'] vs something like f.id and do some magic in __getattr__() and __setattr__()?
Re: Fiona's half-way mark
Author: Sean
Fiona originally had such GeoJSON-like objects with `id`, `geometry`, and `properties` attributes. But as I coded, I kept asking myself "this is redundant: why not just use GeoJSON-like mappings?" This question never went away, and I finally decided to ditch the classes and just use dicts. Dicts and other mappings are thoroughly documented, well-tested, and built-in. The GeoJSON format is also very well known these days and maps easily to Python dicts. I feel like I'm trading less code for more usability: win-win.
Re: Fiona's half-way mark
Author: Howard Butler
Most of your performance win is probably related to cython vs SWIG. SWIG can generate terrible Python from a performance perspective.
What's cython's story with regard to PyPy or IronPython? A Fiona based on ctypes would get access to those interpeters for practically no effort. Maybe cython's story with regard to that is the same...
What about coordinate systems? Do they live in Fiona? Should they?
Re: Fiona's half-way mark
Author: Sean
I'm not interested in IronPython anymore. For PyPy, ctypes definitely seems to be the way to go: http://codespeak.net/pypy/dist/pypy/doc/extending.html. Cython's PyPy story isn't so clear. Switching Fiona to ctypes shouldn't be that hard.

Comments
Re: Coordinate reference systems for Fiona
Author: Even Rouault
Sean,
Why not
or something close instead of iterating over each ring/subgeometry part ?
OGR SWIG bindings have a Geometry.Transform() ;-)
Re: Coordinate reference systems for Fiona
Author: Sean
The reason why is that pyproj's transform function is very simple and limited. It operates only on coordinate sequences (Python buffers, to be precise). It doesn't have a concept of geometry or parts or rings. But because of its simple design, you can combine it with Numpy, matplotlib, and the universe of not-GIS Python software.
Geometry.Transform() embodies a number of patterns that I'm deliberately avoiding in my work on Fiona such as excessive object orientation, mutability, and capitalized method names ;) And while it may be easier in the short run, I'm in pursuit of simpler.