Flickr support for ancient world places
I've already written a little about the extra love Pleiades is getting from Flickr on the Pleiades blog. This post is the version for developers, and also appears on the Flickr developer blog: http://code.flickr.com/blog/2011/12/16/pleiades-a-guest-post/. I think this may be my first guest blog post ever.
Background
In August of 2010, Dan Pett and Ryan Baumann suggested that we coin Flickr machine tags in a "pleiades" namespace so that Flickr users could assert connections between their photos and places in antiquity and search for photos based on these connections. Ryan is a programmer for the University of Kentucky's Center for Visualization and Virtual Environments and collaborates with NYU and ISAW on Papyri.info. Dan works at the British Museum and is the developer of the Portable Antiquities Scheme's website: finds.org.uk. At about the same time, ISAW had launched its Flickr-hosted Ancient World Image Bank and was looking for ways to exploit these images, many of which were on the web for the first time. AWIB lead Tom Elliott, ISAW's Associate Director for Digital Programs, and AWIB Managing Editor Nate Nagy started machine tagging AWIB photos in December 2010. When Dan wrote "Now to get flickr's system to link back a la openplaques etc." in an email, we all agreed that would be quite cool, but weren't really sure how to make it happen.
As AWIB picked up steam this year, Tom blogged about the machine tags. His
post was read by Dan Diffendale, who began tagging his photos of cultural
objects to indicate their places of origin or discovery. In email, Tom and Dan
agreed that it would be useful to distinguish between findspot and place of
origin in photos of objects and to distinguish these from photos depicting the
physical site of an ancient place. They resolved to use some of the predicates
from the Concordia project, a collaboration between ISAW and the Center for
Computing in the Humanities at King's College, London (now the Arts and
Humanities Research Institute), jointly funded by the NEH and JISC. For
findspots, pleiades:findspot=PID (where PID is the short key of a Pleiades
place) would be used. Place of origin would be tagged by pleiades:origin=PID.
A photo depicting a place would be tagged pleiades:depicts=PID. The original
pleiades:place=PID tag would be for a geographic-historic but otherwise
unspecified relationship between a photo and a place. Concordia's original
approach was not quite RDF forced into Atom links, and was easily adapted to
Flickr's "not quite RDF forced into tags" infrastructure.
I heard from Aaron Straup Cope at State of the Map (the OpenStreetMap annual meeting) in Denver that he'd seen Tom's blog post and, soon after, that it was on the radar at Flickr. OpenStreetMap machine tags (among some others) get extra love at Flickr, meaning that Flickr uses the machine tag as a key to external data shown on or used by photo pages. In the OSM case, that means structured data about ways ways and nodes, structured data that surfaces on photo pages like http://flickr.com/photos/frankieroberto/3396068360/ as "St George's House is a building in OpenStreetMap." Outside Flickr, OSM users can query the Flickr API for photos related to any particular way or node, enabling street views (for example) not as a product, but as an grassroots project. Two weeks later, to our delight, Daniel Bogan contacted Tom about giving Pleiades machine tags the same kind of treatment. He and Tom quickly came up with good short labels for our predicates and support for the Pleiades machine tags went live on Flickr in the middle of November.
On the Flickr Side
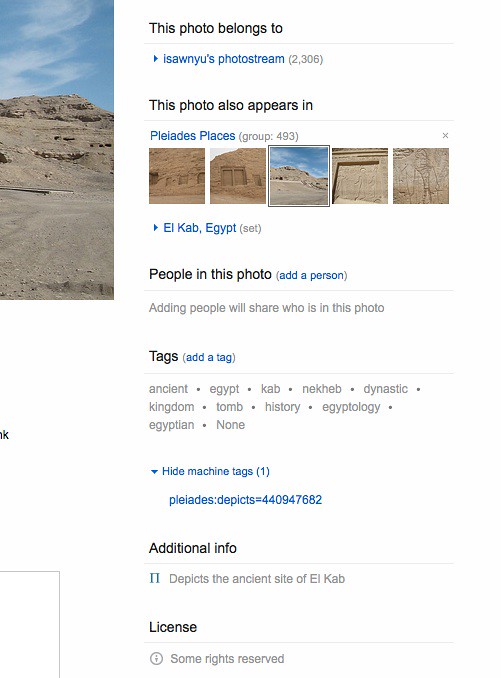
Here's how it works on the Flickr side, as seen by a user. When you coin a new,
never before used on Flickr machine tag like pleiades:depicts=440947682 (as
seen on AWIB's photo Tombs at El Kab by Iris Fernandez), Flickr fetches the
JSON data at http://pleiades.stoa.org/places/440947682/json in which the
ancient place is represented as a GeoJSON feature collection. A snippet of
that JSON, fetched with curl and pretty printed with python
is shown here:
[Gist: https://gist.github.com/1488270]
The title is extracted and used to label a link to the Pleiades place under the photo's "Additional info".
Flickr is in this way a user of the Pleiades not-quite-an-API that I blogged about two weeks ago.
Flickr as external Pleiades editor
On the Pleiades end, we're using the Flickr website to identify and collect openly licensed photos that will serve as portraits for our ancient places. We can't control use of tags but would like some editorial control over images, so we've created a Pleiades Places group and pull portrait photos from its pool. The process goes like this:

We're editing (in this one way) Pleiades pages entirely via Flickr. We get a kick out of this sort of thing at Pleiades. Not only do we love to see small pieces loosely joined in action, we also love not reinventing applications that already exist.
Watch the birdie
This system for acquiring portraits uses two Flickr API methods:
flickr.photos.search and flickr.groups.pools.getPhotos. The guts of it
is this Python class:
class RelatedFlickrJson(BrowserView): """Makes two Flickr API calls and writes the number of related photos and URLs for the most viewed related photo from the Pleiades Places group to JSON like {"portrait": { "url": "http://flickr.com/photos/27621672@N04/3734425631/in/pool-1876758@N22", "img": "http://farm3.staticflickr.com/2474/3734425631_b15979f2cd_m.jpg", "title": "Pont d'Ambroix by sgillies" }, "related": { "url": ["http://www.flickr.com/photos/tags/pleiades:*=149492/"], "total": 2 }} for use in the Flickr Photos portlet on every Pleiades place page. """ def __call__(self, **kw): data = {} pid = self.context.getId() # local id like "149492" # Count of related photos tag = "pleiades:*=" + pid h = httplib2.Http() q = dict( method="flickr.photos.search", api_key=FLICKR_API_KEY, machine_tags="pleiades:*=%s" % self.context.getId(), format="json", nojsoncallback=1 ) resp, content = h.request(FLICKR_API_ENDPOINT + "?" + urlencode(q), "GET") if resp['status'] == "200": total = 0 photos = simplejson.loads(content).get('photos') if photos: total = int(photos['total']) data['related'] = dict(total=total, url=FLICKR_TAGS_BASE + tag) # Get portrait photo from group pool tag = "pleiades:depicts=" + pid h = httplib2.Http() q = dict( method="flickr.groups.pools.getPhotos", api_key=FLICKR_API_KEY, group_id=PLEIADES_PLACES_ID, tags=tag, extras="views", format="json", nojsoncallback=1 ) resp, content = h.request(FLICKR_API_ENDPOINT + "?" + urlencode(q), "GET") if resp['status'] == '200': total = 0 photos = simplejson.loads(content).get('photos') if photos: total = int(photos['total']) if total < 1: data['portrait'] = None else: # Sort found photos by number of views, descending most_viewed = sorted( photos['photo'], key=lambda p: p['views'], reverse=True ) photo = most_viewed[0] title = photo['title'] + " by " + photo['ownername'] data['portrait'] = dict( title=title, img=IMG_TMPL % photo, url=PAGE_TMPL % photo ) self.request.response.setStatus(200) self.request.response.setHeader('Content-Type', 'application/json') return simplejson.dumps(data)
[Gist: https://gist.github.com/1482469]
The same thing could be done with urllib, of course, but I'm a fan of httplib2. Javascript on Pleiades place pages asynchronously fetches data from this view and updates the DOM. The end result is a "Flickr Photos" section at the bottom right of every place page that looks (when we have a portrait) like this:
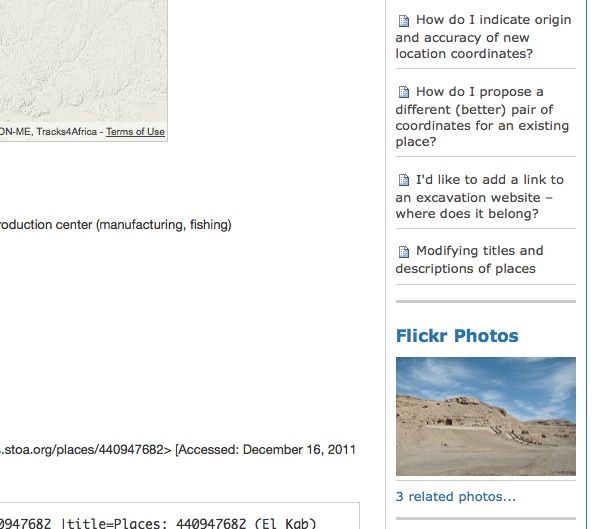
We're excited about the extra love for Pleiades places and can clearly see it
working. The number of places tagged pleiades:*= is rising quickly – up 50%
just this week – and we've gained new portraits for many of our well-known
places. I think it will be interesting to see what developers at Flickr, ISAW,
or museums make of the pleiades:findspot= and pleiades:origin= tags.
Thanks
We're grateful to Flickr and Daniel Bogan for the extra love and opportunity to blog about it. Work on Pleiades is supported by the NEH and ISAW. Our machine tag predicates come from a NEH-JISC project – still bearing fruit several years later.