Modeling historical places for Pleiades
There have been a few recent calls for humanities researchers and informaticians to write more about their models of temporal and geographic data. The one I'm working on (Pleiades, a gazetteer and more) is preparing to evolve, so this is a good time to write about its current state and future directions.
That a place is more than its longitude and latitude coordinates has long been recognized. It's not just that a single point insufficiently describes a place known as "Lattara", but also that no ensemble of 2D or 3D geometric objects – points, lines, or polygons – sufficiently describes that place. Place is also determined by history, by language, by populations, by human experience. Yi-fu Tuan [1] writes:
Experience constructs place at different scales. The fireplace and the home are both places. Neighborhood, town, and city are places: a distinctive region is a place, and so is a nation.
Pleiades is primarily concerned with two characteristics of ancient world places: locations and names. We consider these distinct entities. The cardinality and navigability of the relationships are not much different than those in the CIDOC CRM [2]. In our case we have accompanying assertions and evidence that only make sense within the context of a place, so we have a composition relationship.

Among other attributes, Locations and Names have attested time periods (shown) with confidence measures and evidence (not shown). Temporal modeling isn't something we're going to get into here; in brief, Pleiades has an open vocabulary of time periods that can grow to suit users. The initial time periods (inherited from the Barrington Atlas) are quite coarse, but suffice for study or visualization of change between major eras. One can think of Names and Locations as broad events instead of snapshots in time and thereby partly escape the conceptual box of time-ordered footprints identified by Mostern and Johnson [3]. Politics or the movement of people sweep away old names and bring new ones. Settlements grow and fade, coastlines shift. Pleiades can document what is known about these episodes.
In the CRM, names and coordinates are generalizations of "E44 Place
Appellation". We don't model this in the same way, although some of the
intended consequences manifest themselves in the way we implement composition:
one can readily find "place 42" by following the links embedded in the
representations at (for example) /places/42/name(foo) or
/places/42/location(bar) and in that sense, they do label the place.
The CRM, by the way, is as open-minded (or more) about place as Tuan: the deck of the H. M. S. Victory is considered a place and the lower right corner of a painting depicting Admiral Nelson's death is considered a place. We wouldn't prevent a user from submitting the bottom step of the Scalae Gemoniae as a place, I suppose, but Pleiades isn't aimed at this scale.
There's a lot we can do with the simple model shown above. We can identify unlocated places mentioned in ancient texts but never conclusively surveyed by archaeologists. We can identify the sites of excavated ancient places that yield no clue to their names. We can identify fictional places. We can collect arguments and evidence. We can share identifiers across the web. Yet, there are a few interesting ways to look at places that we can't support.
We don't allow aggregation of places to create hierarchies or places that are known only by sum of their parts. See for example Smith's [4] chapter on Gallia Cisalpina (emphasis mine):
The Boii occupied the country along the south side of the Po to the foot of the Apennines, and the northern slopes of these mountains. Their limits can only be approximated to by mentioning the towns within their territory. Bononia, originally called Felsina, when it was an Etruscan city, was one of them, and Mutina and Parma were two others. Placentia, near the junction of the Trebia and the Po, may have been within their limits; if it was not, we must place it in the country of the Ananes.
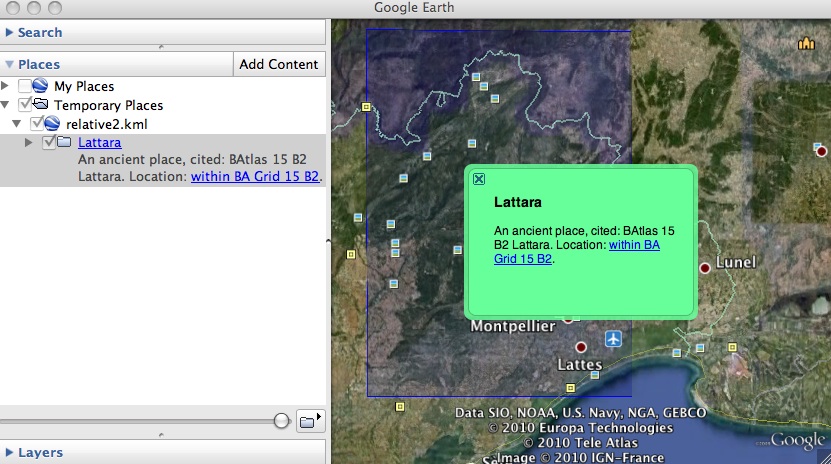
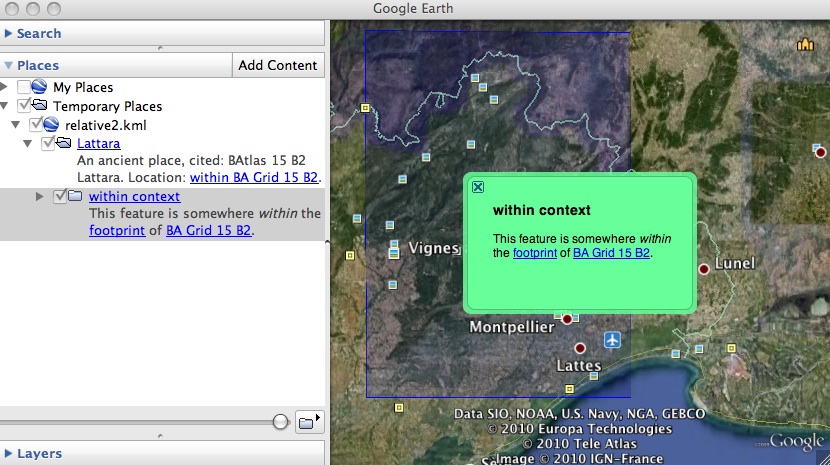
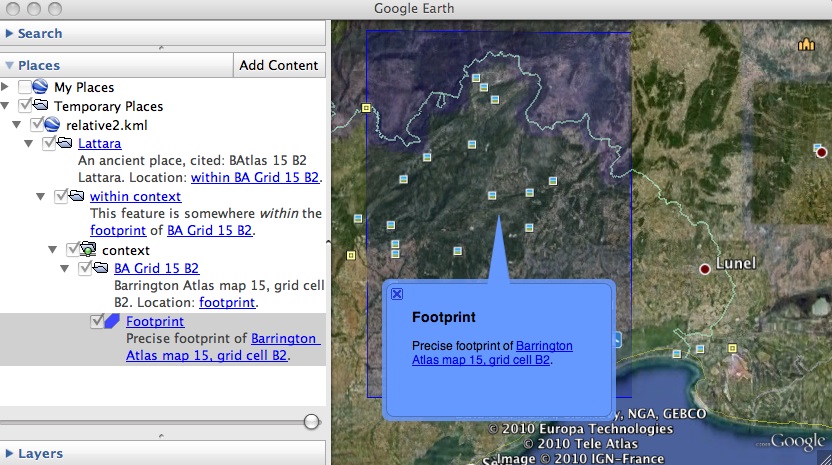
We've special-cased fuzzy locations such as "within the Barrington Atlas map 15 grid cell B2" but don't otherwise have a way for users to express fuzzy or relative locations like those in the same chapter (emphasis mine):
A new band according to Livy's authorities soon crossed the Alps by the same pass, the Cenomani (Liv. 5.35) under Elitovius, and occupied the places where in Livy's time Brixia (Brescia) and Verona were: the Libui were the previous occupiers of these parts. Livy may not have perceived that he has already mentioned (5.34) the Aulerci as Gallic invaders of Italy, and that the Cenomani were a division of the Aulerci. [CENOMANI] Cato found a tradition somewhere (Plin. Nat. 3.19) that the Cenomani once dwelt near Massilia (Marseille) in the country of the Volcae, which, if the tradition is true, may have been during their migration from their original country between the Loire and the Seine. The Cenomani (Livy) were followed by the Salluvii, who settled near “an ancient people, Laevi, Ligures,” as some texts have it, “who dwelt about the river Ticinus.” But here Livy has not observed, though he knew the fact, that the Salluvii or Salyes were Ligurians, and dwelt between the Lower Rhone and the Alps. In this passage (5.35) perhaps he may mean the Salassi.
The Barrington Atlas map-by-map directories include entries for ancient road networks such as this stretch of the Via Postumia in Map 39:
Augusta Taurinorum → Forum Vibii → *Forum Germanici → Pedo(na)
but we're not yet able to store these in a form that allows network analysis.
Changes to the model that would allow us to cover the new use cases are sketched out below.

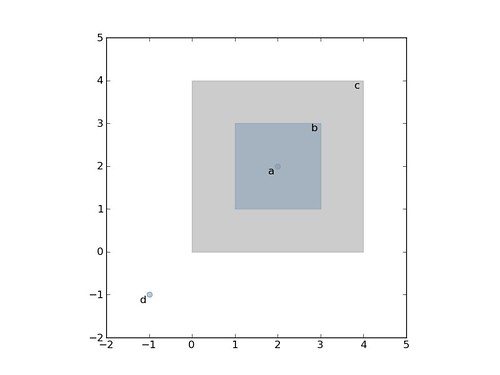
The Feature interface in the diagram allows a clearer diagram. In practice it will be provided by Place entities. The "connected to" relationship would let us form graphs and do simple analysis of trade networks even in the absence of surveyed roadways. The "has part" relationship would let us generate rough spatial extents for aggregate places without falsely asserting any exact boundaries to them. An set of "relates to" relationships will let us put fuzzily or relatively located places "on the map".
I'm simultaneously writing about the effort to design representations of these entities for the web here and here. In the near future, I'd like to explain more about the evidentiary entities in light of Sebastian Heath's research.
By coincidence, as I'm writing this and citing Ruth Mostern (disclosure: Prof. Mostern was on the original Pleiades steering committee), I got word of the publication of version 1.1 of the Digital Gazetteer of the Song Dynasty (CC by-nc-sa) she has produced with Elijah Meeks. Their entity model is shown at http://songgis.ucmercedlibrary.info/?page_id=94.





Comments
Pylons
Author: Kurt Schwehr
That's quite the list of python packages to cover. Thanks for the post as I had been interest in pylons, but I got annoyed that they were not doing point release tars before. You caused me to go an look... and they now have a pylons 1.0 tar. Yeah!