I'm working on a map that shows all locations associated with an ancient place.
The map is part of the HTML representation of the place (or more specifically:
the resource that describes the place) and the data that goes into the map
comes from a JSON representation of the place. I've written before about this
hypertext-based design.
For this particular application, the ancient place is modeled as a GeoJSON
feature collection and locations as GeoJSON features. A feature collection has
a list of features and, GeoJSON being under-specified in comparison to other
GIS standards, clients can't expect any particular ordering of the features.
OpenLayers renders them in the order they are listed. We were running into
trouble with feature collections that listed large feature patches after
smaller feature patches or point features. The big features would be rendered
last by OpenLayers and would pave over the smaller features, making it
impossible to select them.
OpenLayers should continue to render features in the given order; predictable behavior is a very good thing. The answer, for us, is to get the
features properly sorted in our JSON representation: a feature should be
listed before the features it contains. Solved. We don't even need fancy
geoprocessing to do it. This is easily accomplished using the sorting
capability built into Python as sorted(), with a little help from Shapely.
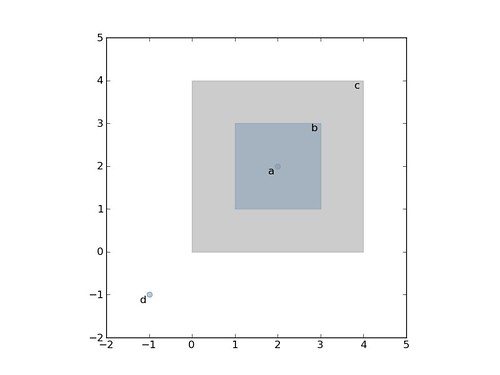
Let's say we have 4 stereotypic features: a point that is contained by a
polygon which is itself contained by another polygon, and a free spirited point
contained by none.
>>> a = {'type': 'Point', 'coordinates': [2, 2]}
>>> b = {'type': 'Polygon', 'coordinates': [[[1, 1], [1, 3], [3, 3], [3, 1]]]}
>>> c = {'type': 'Polygon', 'coordinates': [[[0, 0], [0, 4], [4, 4], [4, 0]]]}
>>> d = {'type': 'Point', 'coordinates': [-1, -1]}
And that copies of these are collected into a list like
>>> features = [c, a, d, b, c]
Render this with OpenLayers and the big polygon (c) covers everything except
point (d). Rendering them in reverse doesn't help because there's another big
polygon at the other end of the list.
Sorting using the default key (comparison by characters) seems to almost
produce the right order for the map:
>>> from pprint import pprint
>>> pprint(sorted(features, reverse=True))
[{'type': 'Polygon', 'coordinates': [[[1, 1], [1, 3], [3, 3], [3, 1]]]},
{'type': 'Polygon', 'coordinates': [[[0, 0], [0, 4], [4, 4], [4, 0]]]},
{'type': 'Polygon', 'coordinates': [[[0, 0], [0, 4], [4, 4], [4, 0]]]},
{'type': 'Point', 'coordinates': [2, 2]},
{'type': 'Point', 'coordinates': [-1, -1]}]
The points are ordered after the polygons, which is good, but the bigger
polygons still cover the contained one, not what we want. We'll need a
different sorting key, one that considers whether features are spatially
within another.
As explained in the Python Sorting HowTo, we can define a key function that
operates on each list element and returns a value for comparison. Our key
function will be a wrapper class that implements __lt__() using Shapely's
binary within() predicate and asShape() adapter.
from shapely.geometry import asShape
class Within(object):
def __init__(self, o):
self.o = o
def __lt__(self, other):
return asShape(self.o).within(asShape(other.o))
As the howto says, the less than comparison is guaranteed to be used in
sorting. That's what we'll rely on to spatially sort, and is why we're using within() in reverse instead of the contains() predicate. Trying it out on features
b and c, we see that it works:
>>> b < c
False
>>> Within(b) < Within(c)
True
Now, the wrapper is used to sort by spatial containment like so
>>> pprint(sorted(features, key=Within, reverse=True))
[{'type': 'Point', 'coordinates': [-1, -1]},
{'type': 'Polygon', 'coordinates': [[[0, 0], [0, 4], [4, 4], [4, 0]]]},
{'type': 'Polygon', 'coordinates': [[[0, 0], [0, 4], [4, 4], [4, 0]]]},
{'type': 'Polygon', 'coordinates': [[[1, 1], [1, 3], [3, 3], [3, 1]]]},
{'type': 'Point', 'coordinates': [2, 2]}]
Voila: feature d is within no other feature and is listed first; the other
features are listed as we wish. This little trick is now bound for the Shapely manual.