For spork's sake no
No, Vish (who asked for criticism), no:
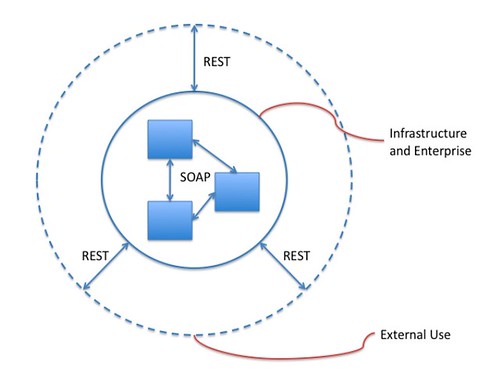
I am also hoping that in the near future, ESRI’s SOAP and REST API have the exact same service contracts that are just exposed at different endpoints. Currently, the SOAP API seems to more feature-filled and the REST API seems to be playing catch up. Aren’t SOAP and REST just different ways of accessing the same exact GIS feature set in ArcGIS Server? Alright, I will end the rant right here. :)
REST and RPC are different styles of solutions for different types of problems. Wanting them to be exactly the same misses the point entirely. I'll make a (admittedly Anglo-European biased) dining analogy, because it's getting to be the time of day when I'm pondering dinner: a spork is no match for a spoon when it comes to delivering soup to your mouth, and is equally ill-suited for eating a salad. The difference between spoon and fork is due to good, divergent design, not design gone wrong.
Comments
Re: For spork's sake no
Author: David
Hybrid bike anyone?
Re: For spork's sake no
Author: Sean
Good one. Nothing wrong with a hybrid bike, but two of them? Which one do you take on a long and technical single-track ride? The blue one? The red one? It seems like ESRI users might be making design choices based on similarly wrong facets.
Re: For spork's sake no
Author: bob
I disagree on the analogy, using the car example (in this case a truck example), SOAP (IMHO) is Chevy 1500 pickup and REST is a Ford F150.
Both _can_ carry the same payload, it's just up to the developer to implement it that way. Where I work we pass the same data over all of our transport interfaces. That way the non-SOAP users (typically Unix/Java/Perl groups) can get the same data as the SOAP users (typically Windows/.Net users).
Re: For spork's sake no
Author: Sean
No. My analogy was weak, but yours is completely misbegotten, bob. You're missing the point of having different architectural styles. SOAP (and other RPC) abstract away the network. You trade scalability for productivity. RPC doesn't scale out, but you can apply your familiar object-oriented and MVC practices and tools. In the REST style you trade latency -- more requests, more following of links between loosely coupled components -- and maybe even productivity (fewer fancy tools) for scalability.