Intrigued by Mike Bostock's TopoJSON
project, I've written a module of functions that convert TopoJSON objects to plain
old GeoJSON objects: https://github.com/sgillies/topojson/blob/master/topojson.py.
I learned a couple of new things about slicing along the way: None is the
same as nothing in slicing syntax,
>>> range(4)[None:None] == range(4)[:] == [0, 1, 2, 3]
True
and expressions in slice indices are powerful things. I'm using them to truncate or
reverse lists of coordinates depending on their index in another list. For example, say I have a list of words in which the last character of one word is the same as the first character of the following word, and I'd like to concatenate them while removing the duplicates where they join.
>>> words = ["abcd", "defg", "ghij"]
>>> from itertools import chain
>>> "".join(chain(*
... [word[i > 0:] for i, word in enumerate(words)] ))
'abcdefghij'
There is implicit conversion to type int in the slice expression word[i > 0:] above: True becomes 1, False becomes 0. word[0:] is the orginal word, while word[1:] is a copy with the first character omitted.
Next, say I want to describe a particular way of concatenating the words using a list of integers, the values of which correspond to indices of the words list. I want [0, 1, 2] to come out as above, 'abcdefghij', and a list of complements like [~2, ~1, ~0] (or equivalently, [-3, -2, -1]) to come out as 'jihgfedcba'. All this takes is another slice expression that reverses words when their index < 0: [::j >= 0 or -1].
>>> def merge(word_indices):
... return "".join(chain(*
... [words[j if j>=0 else ~j][::j >= 0 or -1][i > 0:] \
... for i, j in enumerate(word_indices)] ))
...
>>> merge([0,1,2])
'abcdefghij'
>>> merge([-3,-2,-1])
'jihgfedcba'
This is more or less how you merge TopoJSON arcs into GeoJSON geometry coordinates.
The program below was made for an IPython Notebook with pylab inline. A lot
of the code has appeared in my recent posts. Ultimately, there's a function to
project shapes (the "geoms") and a rendering function that's used to fold them
into a map image.
from descartes import PolygonPatch
from functools import partial, reduce
import json
import logging
from pyproj import Proj, transform
import urllib
from topojson import geometry
# Fetch some US states TopoJSON.
data = urllib.urlopen(
"https://raw.github.com/mbostock/topojson/master/examples/topo/us-states.json"
).read()
topology = json.loads(data)
scale = topology['transform']['scale']
translate = topology['transform']['translate']
arcs = topology['arcs']
# The following functions support LLC projection of shapes.
def transform_coords(func, rec):
# Transform record geometry coordinates using the provided function.
# Returns a record or None.
try:
if rec['type'] == "Polygon":
new_coords = list(zip(*func(*zip(*ring))
) for ring in rec['coordinates']
elif rec['type'] == "MultiPolygon":
new_coords = []
for part in rec['coordinates']:
new_part_coords = list(zip(*func(*zip(*ring))
) for ring in part)
new_coords.append(new_part_coords)
return {'type': rec['type'], 'coordinates': new_coords}
except Exception, e:
# Writing untransformed features to a different shapefile
# is another option.
logging.exception(
"Error transforming record %s:", rec)
return None
epsg4326 = Proj(init="epsg:4326", no_defs=True)
lcc = Proj(
proj="lcc",
lon_0=-96.0,
lat_0=23.0,
lat_1=23.0,
lat_2=60.0,
ellps="WGS84",
datum="WGS84",
units="m",
no_defs=True)
transform_lcc = partial(transform, epsg4326, lcc)
lambert = partial(transform_coords, transform_lcc)
# The rendering of a single shape is done by the following.
BLUE = "#6699cc"
RED = "#cc6666"
def add_record(axes, rec, fc=BLUE, ec=BLUE, alpha=1.0):
"""Makes a patch of the record's geometry and adds it to the axes."""
if rec['type'] == "Polygon":
axes.add_patch(
PolygonPatch(rec, fc=fc, ec=ec, alpha=alpha) )
elif rec['type'] == "MultiPolygon":
for part in rec['coordinates']:
axes.add_patch(
PolygonPatch(
{'type': "Polygon", 'coordinates': part},
rec, fc=fc, ec=ec, alpha=alpha ))
axes.autoscale(tight=False)
return axes
add_feature_alpha = partial(add_record, alpha=0.5)
# Transform the relative coordinates of geometries to absolute coordinates.
geoms = [
geometry(
obj,
arcs,
scale,
translate ) for obj in topology['objects'][0]['geometries'] ]
# Fold all the geoms up into a nice projected map image.
figsize(12, 12)
gca().set_aspect('equal')
reduce(add_feature_alpha, map(lambert, geoms), gca())
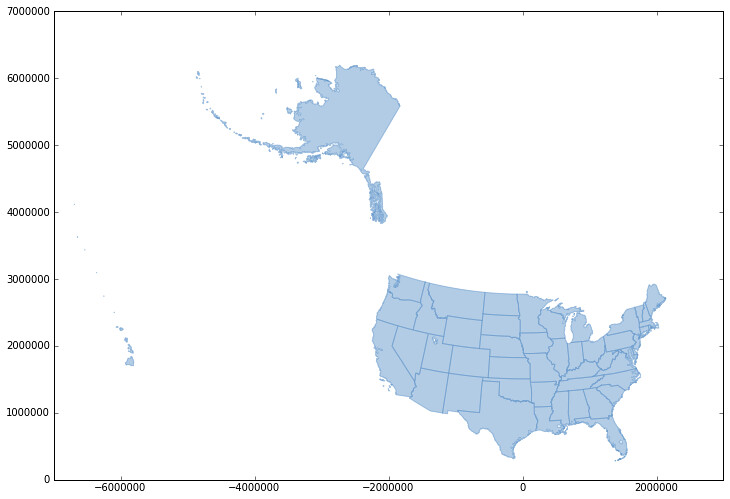
The result:
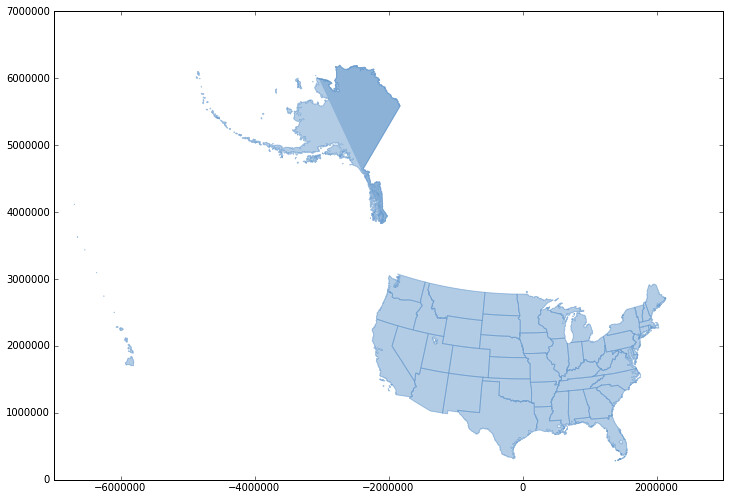
Alaska is a little strange. I'll look into it.
Update (2012-11-21): I fixed a bug with locating the arc at index 0 and Alaska now looks fine.